Part 2 showed the pixel-MSE smear: when the next-frame distribution is bimodal, MSE forces an averaged blur. The output target is wrong.
Yann LeCun’s response is to predict in embedding space instead. An encoder maps each frame to a vector. Two encoders share weights. They are trained so that two views of the same underlying scene produce similar embeddings. The encoder is then free to throw away unpredictable detail (which way the ball bounced) while keeping what is predictable. No pixel-level commitment, no smear.
This is a joint embedding architecture, an idea LeCun first used in 1990s work on signature verification. Code for this part is in part2_jepa/ of the repo.
The setup
Two augmented views of the same frame go through copies of an encoder. The objective is to make the two embeddings agree.
v1 = augment(x)
v2 = augment(x)
z1 = encoder(v1)
z2 = encoder(v2)
loss = F.mse_loss(z1, z2)This works as written for about ten seconds before the trivial solution wins.
Representation collapse
Run the training above and the encoder learns to output the same vector for every input. MSE goes to zero. The model has solved the loss function and learned nothing.
This is representation collapse. Any sufficient-capacity encoder under a similarity-only loss can find a constant output and stop. There is no signal in the loss telling it to keep its dimensions distinguishable.
I ran the naive setup against the bouncing-ball dataset, taking 256-frame batches and projecting the resulting 128-dim embeddings to 2D via PCA every 50 steps. The left panel is the naive run; every embedding migrates toward a single point. The right panel is the same encoder trained with the Barlow Twins (2021) loss, which I’ll cover next.

Final embedding standard deviation across all 128 dims, averaged: naive 0.00006, Barlow Twins 0.36. The naive encoder has compressed all 200 frame variations into the same vector.
Barlow Twins
The Barlow Twins paper (Zbontar, Jing, Misra, LeCun, Deny) takes its name from Horace Barlow, the neuroscientist who hypothesised in 1961 that biological vision systems work by reducing redundancy between neurons. The fix for collapse is to apply that same idea to the encoder’s output dimensions.
Stack the two batches of embeddings and compute the cross-correlation matrix between dimensions:
def barlow_loss(z1, z2, off_w=0.005):
n, d = z1.shape
z1 = (z1 - z1.mean(0)) / (z1.std(0) + 1e-5)
z2 = (z2 - z2.mean(0)) / (z2.std(0) + 1e-5)
cc = (z1.T @ z2) / n # (d, d) cross-correlation
on_diag = (cc.diag() - 1).pow(2).sum()
off_diag = (cc - cc.diag().diag()).pow(2).sum()
return on_diag + off_w * off_diagThe cross-correlation matrix has one row per encoder dimension. Each cell measures how correlated dimension i of encoder A is with dimension j of encoder B across the batch.
- On-diagonal entries should be 1: dimension
iof A should match dimensioniof B (the same view-invariance objective as the naive setup). - Off-diagonal entries should be 0: different dimensions should be uncorrelated, which forces the encoder to use its full embedding space rather than collapsing dimensions onto each other.
The off-diagonal penalty is what prevents collapse. A constant-output encoder produces an undefined cross-correlation matrix (zero variance), which the loss heavily penalises through the standardisation step.
Watching the cross-correlation matrix during training, the off-diagonals fade toward zero as the on-diagonals saturate at 1:
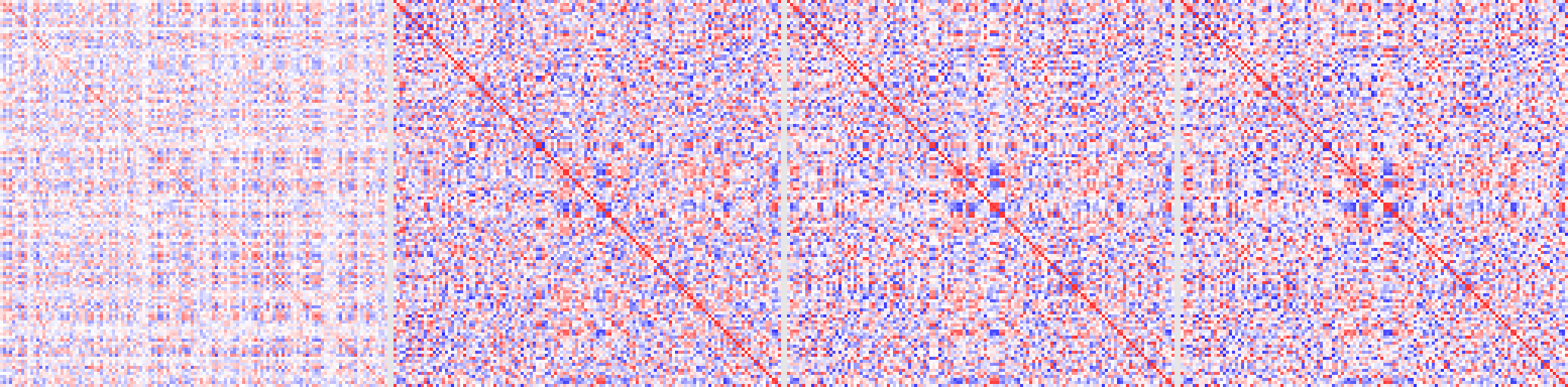
Four panels, left to right: step 0, step 375, step 750, step 1500. Red is positive correlation, blue is negative, white is zero. The diagonal turns red and stays there; the off-diagonals fade to white.
VICReg: simpler
VICReg (Bardes, Ponce, LeCun, 2022) replaces the cross-correlation matrix with three explicit terms:
- Invariance: MSE between corresponding embeddings. Same as the naive loss.
- Variance: each dimension’s standard deviation across the batch must be at least 1. A hinge loss penalises dimensions that collapse toward zero variance.
- Covariance: the off-diagonal entries of the embedding’s covariance matrix should be near zero. Decorrelates dimensions.
The variance term is what explicitly stops collapse: a constant output has zero variance and pays the maximum penalty. Decorrelation no longer has to do double duty.
sim = F.mse_loss(z_pred, z_next)
var = variance_loss(z_t) + variance_loss(z_next)
cov = covariance_loss(z_t) + covariance_loss(z_next)
loss = 25.0 * sim + 25.0 * var + 1.0 * covThis is what the project’s train_jepa.py uses. It’s stable enough on the toy that I haven’t had to tune the weights.
LeJEPA: simpler still
In November 2025, Balestriero and LeCun published LeJEPA, which replaces VICReg’s three-term cocktail with a single regulariser called SIGReg. SIGReg pushes the embedding distribution toward an isotropic Gaussian by minimising a closed-form discrepancy. The math is heavier but the implementation is about fifty lines and has one hyperparameter rather than three.
I haven’t ported SIGReg to this toy yet (it’s a few hours of work and the existing VICReg implementation already trains stably). Each iteration of these regularisers drops complexity rather than adding it: Barlow Twins (one matrix penalty) → VICReg (three explicit terms in place of the matrix) → LeJEPA (one closed-form regulariser, one hyperparameter).
What this gets us
Predict-the-embedding training does not give us sharper next-frame predictions on this toy. The averaging problem from Part 2 is information-theoretic - a single-frame input does not contain enough information to disambiguate which way the ball is bouncing, so any predictor under MSE in any space will average. Joint embedding training does not escape that.
What it does give us is an encoder whose 128-dim output represents the input frame in a structured, decorrelated way. The next post takes that encoder and applies it to real images.
Next
Part 4 takes a production-grade joint-embedding encoder (DINOv2 in the demo, DINOv3 in spirit) and runs it on a still image. Click on a patch and the model returns a similarity heatmap showing which other patches encode the same semantic content. That’s the JEPA-family encoder doing on real data what Barlow Twins, VICReg, and LeJEPA are designed for.